ch09 · 预训练(Pretrain)¶
ch06 训过 1M 小 GPT,那不算预训练,那叫 "过拟合一段莎士比亚"。
真正的预训练是:几百 GB 文本 + 几亿到几千亿参数 + 几天到几月训练时间。工程难度全在三个字:省(显存)、稳(不发散)、快(吞吐高)。
本章不要求亲自跑大模型,目标是把 M4 echo-mini Pretrain 脚本要用的概念全摸清。
学习目标¶
- 能写出 CLM 训练目标的 loss 公式,知道 input/labels 怎么 shift
- 理解数据 packing 为什么必要,"有效 token 比例"指什么
- 区分混合精度 / 梯度累积 / gradient checkpointing 三件套各自换的是什么
- 对 scaling law 有数量级直觉:参数量、数据量、算力是怎么挂钩的
前置依赖¶
- ch04(优化器 / lr 调度)、ch06(Transformer 架构 + 因果 mask)
1. CLM 训练目标¶
Causal Language Modeling = 给定前文,预测下一个 token。 GPT 系全用这个目标,是当下 "预训练" 的同义词。
1.1 loss 公式¶
序列 x = [x₁, x₂, ..., xₙ],模型 θ:
x_{<t} 表示位置 t 之前的所有 token,即 [x₁, ..., x_{t-1}]。整个 loss 就是把每个位置 "用前文预测它自己" 的负对数似然加起来取平均。
工程上一次性算所有位置(teacher forcing + causal mask),不是循环 t。
teacher forcing:训练时每个位置的输入都用真实 token,而不是用模型上一步自己的预测。这样 n 个位置可以并行算 loss,不需要像推理那样自回归一步步走;代价是训练与推理的 token 分布有 gap(exposure bias),CLM 量级语料下基本不构成问题。
exposure bias 补充:训练时前文 100% 正确(ground-truth),推理时前文来自模型自身预测——一旦某步出错,后续输入偏离训练分布,误差逐步累积。大规模语料下 next-token 预测精度足够高,出错概率本身很低,因此该 gap 在实践中(GPT 系列)未需专门修补。
1.2 input / labels 怎么对齐¶
公式说 "用前文预测下一个 token",落到代码需要两样东西:喂给模型的前文(input)和每个位置的正确答案(labels)。labels 不需要人标——直接从原文右移一位自动得到,这也是 "自监督" 的含义。
原始 ids: [w0, w1, w2, w3, w4]
input: [w0, w1, w2, w3] # 喂进模型
labels: [w1, w2, w3, w4] # 模型在每个位置要预测下一个
input 是 labels 左移一位。等价写法:
# tokens shape: (B, L+1)
input_ids = tokens[:, :-1] # (B, L)
labels = tokens[:, 1:] # (B, L)
logits = model(input_ids) # (B, L, V)
loss = F.cross_entropy(logits.reshape(-1, V), labels.reshape(-1))
HF transformers 里更常见是直接给
labels=tokens让模型内部 shift(ch06 全景图及练习代码中已见过),等价。
1.3 ignore_index 与 padding¶
batch 内样本长度不同,短的需要 padding 补齐。但 pad 位置没有真实内容,"预测 pad 的下一个" 毫无意义——如果参与 loss,模型会学到纯噪声。
做法:把不想学的位置 label 设成 -100,F.cross_entropy(ignore_index=-100) 自动跳过(不算 loss、不回传梯度)。
真实序列: [今, 天, 好, <eos>]
padding 后: [今, 天, 好, <eos>, <pad>, <pad>]
input: [今, 天, 好, <eos>, <pad>]
labels: [天, 好, <eos>, -100, -100]
↑ pad 位,跳过
后续章 SFT(Supervised Fine-Tuning, 监督微调) 用 loss mask 也是同一招:prompt 部分 label 设 -100,只在 response 位置算 loss。
自检¶
- 为什么 input 和 labels 错一位而不是直接相同?
- 一个 batch 里 50% 是 padding,loss 计算时这 50% 是怎么处理的?
答案速查
-
CLM 学的是
P(之前所有 | 下一个)。如果 input==labels,等于让模型直接抄当前位置 → 任务退化为 identity,没学到任何 "预测" -
如果不处理:pad 位也参与 loss → 模型学会 "看到 pad 后预测什么",纯噪声,污染训练。正确做法:pad 位置的 label 设
-100,cross_entropy 默认 ignore,分母也跳过这些位置
2. 数据 packing¶
2.1 为什么不能直接喂¶
预训练语料是一篇篇文档(可以是论文、博客、代码、书籍、问答社区语料、技术文档等,甚至其他模型的问答),各文档长度天差地别(几十词到几万词都有)。如果按 batch padding:
doc1: 200 tokens
doc2: 50 tokens
doc3: 800 tokens
batch padding 到 800 → doc1 浪费 600 个 pad,doc2 浪费 750 个
短文档为主的语料里 70%+ 算力被 pad 浪费。不能忍。
2.2 packing 怎么做¶
为了解决 2.1 的问题,想到把所有文档拼成一条超长 token 流,每个文档之间塞 <eos>,然后按固定窗口 block_size 切(典型值 1024 / 2048 / 4096,与模型最大序列长度对齐):
docs: [doc1] <eos> [doc2] <eos> [doc3] <eos> ...
flat: t1, t2, ..., tN (N 可能上亿)
chunks: flat[0:1024], flat[1024:2048], flat[2048:3072], ... # 此例 block_size=1024
每个 chunk 就是一个训练样本。几乎 0 padding,有效 token 比例 ~100%。
2.3 跨文档污染?¶
2.2 的 chunk 直觉上的问题:packing 后一个 chunk 内可能含半个 doc1 + 整个 doc2 + 半个 doc3。模型在 doc2 开头位置会 "看到" doc1 的尾巴当作上下文 —— 这是污染吗?
工程上默认接受:
<eos>提示了边界信号 —— 见过足够多<eos>...新文档开头的样本后,模型会学到 "看到<eos>就重置话题" 的隐式行为,跨文档影响被自然衰减- 有研究专门做 "document-level attention mask"(同 doc 内才能 attend),收益不大但实现复杂
- 数据量足够大时,这点污染反而像一种隐式数据增强
M4 echo-mini 用最朴素的 packing,不做 doc mask。
自检¶
- packing 后的 batch shape 是什么样?为什么所有 chunk 等长?
- 不做 packing,按 batch padding 处理,"有效 token 比例" 是什么意思?
答案速查
-
(B, block_size),所有 chunk 都精确 block_size 个 token(最后一个不足的丢弃或拼下一 epoch)。等长意味着无 padding,shape 静态,编译/算子都最快 -
=
非 pad token 数 / 总 token 数。padding 占的算力是浪费的。100% 表示无浪费,packing 能做到 >99%;朴素 padding 在变长语料上常 30%–60%
3. 省显存三件套¶
3.1 预训练显存的来源¶
省显存之前先搞清楚:显存到底被谁吃了。看清各块占多少、用什么精度存,才好看出后面每个优化各省了什么。
四个占用主体¶
预训练时 GPU 显存被四件事吃掉:
| 主体 | 是什么 | 占用规模 |
|---|---|---|
| 权重 weights | 模型参数本身,总数记作 N | ∝ N |
| 梯度 gradients | 每个权重对应的 ∂Loss/∂W,形状与权重相同 | ∝ N |
| 优化器状态 optimizer | Adam 为每个参数额外存的动量 | ∝ N(最大头) |
| 激活 activations | 帮助反向用的中间张量 | ∝ B × L |
前三者与参数量 N 成正比,是静态的(模型一定就定了);激活随 batch B × 序列长度 L 增长,是动态的,大 batch / 长序列下往往是最大头。
逐个拆解:
- 权重:模型参数本身(W^Q/W^K/W^V/W^O、FFN、embedding、LN 等)
- 梯度:loss 对每个参数的偏导 ∂Loss/∂W,告诉优化器 "往哪调、调多少"。每个权重一份,所以与权重等大。
- 优化器状态:Adam 额外为每个参数维护一阶动量 m(梯度滑动平均)+ 二阶动量 v(梯度平方滑动平均),用来自适应调步长。两个状态 → 2 倍权重大小,是静态项里最大的一块。
- 激活:前向中间结果(Q/K/V、attention score、FFN 中间层等)、反向要用的张量。它不与 N 直接挂钩,而是随 batch × 序列长度 × 层数 膨胀,这也是为什么三件套里有两个(AMP、checkpointing)专门治它。
回忆 ch04:梯度、动量这些概念在优化器一章讲过,这里只关心它们各占多少显存。
回忆 ch06:FNN 中间层做升维操作,对每个位置独立做非线性变换,把汇聚来的信息进一步提炼、组合成更抽象的特征。需要记录,反向时要用。
精度的差异¶
显存 = 张量个数 × 每个数的字节数。前面只数了"个数"(N、B×L),字节数取决于用什么数值类型:
| 格式 | 全称 | 字节/数 | 精度 | 典型用途 |
|---|---|---|---|---|
| fp32 | 单精度浮点 | 4 | ~7 位有效数字 | 默认训练精度、master weights |
| fp16 | 半精度浮点 | 2 | ~3.3 位有效数字,范围小易溢出 | AMP 计算、推理 |
| bf16 | Brain Float 16 | 2 | ~3.3 位有效数字,范围同 fp32 | AMP 计算(不易溢出,免 loss scaling) |
| fp8 (E4M3 / E5M2) | 8 位浮点 | 1 | 极低精度 | 新一代 GPU 加速训练/推理 |
| int8 | 8 位整数 | 1 | 256 个离散值 | 推理量化(weights-only 或 weight+activation) |
| int4 | 4 位整数 | 0.5 | 16 个离散值 | 极限推理量化(GPTQ/AWQ 等) |
关键对比:fp32→fp16/bf16 字节砍半,显存直接减半;bf16 与 fp16 同样 2 字节,但 bf16 指数位与 fp32 一样宽,几乎不溢出(3.2 细说)。AMP 省显存的本质,就是把一部分张量从 4 字节换成 2 字节。
纯 fp32 基线怎么算¶
PyTorch 默认权重、梯度、优化器状态全用 fp32(每数 4 字节)。设模型 N 参数、batch B、序列长度 L,最朴素基线:
weights: N * 4B (fp32)
gradients: N * 4B (fp32)
optimizer: N * 8B (Adam: m, v 两个状态 × 4B)
activations: B * L * d * num_layers * (常数)
————————————————————————————————————————
~12N + x (activations)
代入 7B:静态项 12 × 7B + x = 84GB + x,光优化器状态就 56GB,x 更是一个巨大的可变量。
那有没有什么手段能够将训练所需的显存降下来呢?
三件套各治一块¶
| 手段 | 主要省什么 | 治哪块 |
|---|---|---|
| AMP(Automatic Mixed Precision) | 张量换 2 字节 → activations 减半 + 矩阵乘吞吐翻倍 | 激活 + 速度 |
| gradient accumulation(梯度累积) | 等效大 batch,不多占显存 | 激活(峰值) |
| Gradient checkpointing | 用时间换 activations 显存 | 激活 |
3.2 自动混合精度(AMP)¶
用 fp16/bf16 算前向反向,关键状态留 fp32。weights+grads 显存减半,但需保留一份 fp32 master weights,换取矩阵乘吞吐 ~2x。
AMP 显存账本对比(以 1B 参数为例):
纯 fp32:
weights 1B × 4B = 4GB
grads 1B × 4B = 4GB
optimizer 1B × 8B = 8GB
activations = X GB (fp32)
合计: 16GB + X(典型配置下 X 可达数十 GB,远超参数项)
启 AMP 后(概念简化,实际 PyTorch 内存布局可能合并部分副本):
fp16 *weights 1B × 2B = 2GB ← 计算用
fp32 master weights 1B × 4B = 4GB ← 保留,更新精度需要
fp16 *grads 1B × 2B = 2GB
fp32 optimizer 1B × 8B = 8GB ← 不变
activations = X/2 GB (fp16)
合计: 16GB + X/2
参数相关项持平(fp16 weights 多 2GB,但 grads 从 4→2 省 2GB,互相抵消),真正赚的是 activations 砍半 + 计算速度翻倍。大 batch / 长序列时 X 远大于 16GB,收益显著。
from torch.amp import autocast
for x, y in loader:
optimizer.zero_grad()
with autocast("cuda", dtype=torch.bfloat16):
logits = model(x)
loss = F.cross_entropy(logits.view(-1, V), y.view(-1))
loss.backward()
optimizer.step()
要点:
- bf16 优于 fp16:动态范围与 fp32 一样,几乎不会溢出。bf16 不需要
GradScaler,上面就是完整写法 - 训练卡 A100/H100 等上 bf16 是标配;本课程的目标卡 3060 12GB 也支持
-
如果你只能用 fp16(V100 之前的老卡 / 某些推理框架):fp16 容易下溢,要套
GradScaler把 loss 放大 K 倍 → backward 后梯度也放大 K 倍 → 跳过 fp16 下溢区间 → step 前再 unscale。代码:
3.3 梯度累积(gradient accumulation)¶
显存装不下大 batch?拆成多个 micro-batch 累加梯度,再一次更新。化整为零(是否有面试被问到的 "2GB 内存处理 10GB 文件" 即视感),等价大 batch。
ACCUM = 8 # 每 8 个 micro-batch 更新一次 → 等效 batch × 8
optimizer.zero_grad()
for i, (x, y) in enumerate(loader):
with autocast("cuda", dtype=torch.bfloat16):
loss = compute_loss(model, x, y) / ACCUM # 别忘了除!
loss.backward() # 梯度累加进 .grad
if (i + 1) % ACCUM == 0:
optimizer.step()
optimizer.zero_grad()
代价:吞吐略降(多次 forward/backward 但只更新一次),换来等效大 batch 的稳定性。
为什么 compute_loss 后要除以 ACCUM?loss.backward() 直接累加梯度。如果不除,等效于把 ACCUM 个 micro-batch 的 loss 直接相加(不是平均),lr 实际放大了 ACCUM 倍。
若需与 fp16 + scaler(见上方的 "如果你只能用 fp16")的 AMP 结合:把
loss.backward()换成scaler.scale(loss).backward(),更新时scaler.step(optimizer); scaler.update(),scaler 与累积过程兼容。
3.4 Gradient checkpointing¶
训练时反向传播算梯度时需要前向的中间结果(activations)。默认行为是前向时全部存着 —— 快但费显存。
Checkpointing 的做法:只存少量 "检查点" 层的输出,其余丢掉;反向到某层发现没存?从最近的检查点重跑前向算出来。时间换空间。
激活显存可降 5–10x,代价是反向时多跑一次前向(~30% 训练时间增加)。
import torch.utils.checkpoint as ckpt
def block_forward(x):
return self.attn(self.ln1(x)) + x # 简化示意
# 用 ckpt 包住每个 block,激活在反向时按需重算
out = ckpt.checkpoint(block_forward, x, use_reentrant=False)
如果你用 HuggingFace transformers 的模型(主流开源 LLM 基本都提供 HF 格式),一行即可开启,不需要手动包每一层:
对应本项目:echo-mini 从零建模,用
ckpt.checkpoint()原始写法;echo 微调 HF 开源底座,用gradient_checkpointing_enable()。
3.5 三件套联合战力(直觉数字)¶
| 配置 | 显存 | 速度 |
|---|---|---|
| 纯 fp32 | 1.0× | 1.0× |
| + AMP (bf16) | 0.55× | 1.7× |
| + grad accum × 4 | 0.55× | 1.5× |
| + ckpt | 0.20× | 1.2× |
grad accum 那行显存与上一行相同——这是对的:每个 micro-batch 仍要完整前向,单次显存占用不变。它省的是 "想跑等效 batch=64 时显存放不下" 的那份显存(你只需 batch=16 的显存就达到等效 64 的训练效果)。
速度列是相对纯 fp32 基线的端到端吞吐(单位 token/s)。+ckpt 这行的 1.2× 是叠加了 AMP 加速后的净效果 —— ckpt 自身让训练慢 ~30%(多一次前向重算),但 AMP 的 ~1.7× 加速能盖住它。
消费卡上想训 100M+ 模型,这三件套基本都得开。
实测对比(3060 12GB,d=512 12 层模型,bench 脚本 03_amp_gradacc_bench.py 产出):
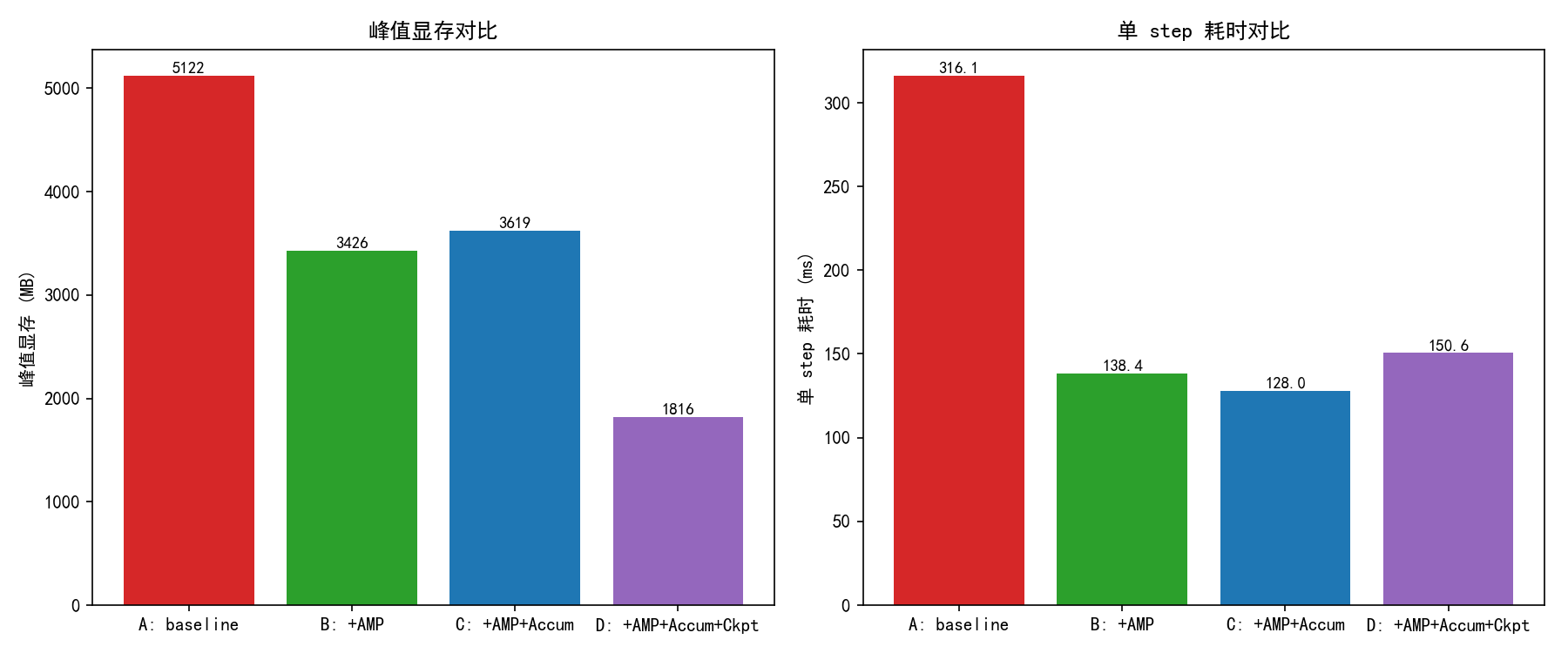
自检¶
- bf16 比 fp16 安全在哪?为什么仍有项目坚持 fp16?
- 梯度累积 8 步,等效 batch 多大?lr 要不要跟着调?
答案速查
-
bf16 的指数位与 fp32 一样(8 位),数值范围一致,几乎不会上下溢;fp16 指数位只有 5 位,小数值容易下溢成 0、大数值容易 overflow。坚持 fp16 多半是老硬件(V100 之前没 bf16)或推理框架限制
-
等效 batch = micro_batch × 8。lr 一般跟随大 batch 经验缩放("linear scale" 或 "sqrt scale"),但具体看模型大小和论文配方;echo-mini 直接抄成熟配方即可
4. Scaling law 直觉¶
Kaplan 2020(OpenAI)发现 loss 与模型大小 N、数据量 D、算力 C 呈幂律关系,奠定了 scaling law 的基础。Chinchilla 2022(DeepMind)修正了其中 "优先堆参数" 的结论,给出 N 与 D 的最优配比。两篇论文共同指导了 LLaMA 系列的训练配方。
4.1 三个量纲(Kaplan 2020)¶
N: 参数量 (params)
D: 训练 token 数 (tokens)
C: 算力 (FLOPs(Floating Point Operations,浮点运算次数)) ≈ 6 * N * D
# 经验近似,前向 2ND + 反向 4ND
记住 C ≈ 6ND。GPU-小时 ≈ FLOPs / (GPU 峰值 × 利用率)。
GPU 峰值:卡的 TFLOPS 利用率:据优化的有无与好坏,在 30%-65%
这个 6ND 的近似对 dense Transformer(每个 token 经过全部参数,区别于 MoE 专家模型只激活部分参数)在参数量远大于序列长度的典型预训练场景下成立,attention 的 O(L²) 项在 L < d 时可忽略。当 L 很长(>10k)或 MoE 场景需要更精细的公式。
4.2 Chinchilla 最优配比¶
训练时面临的更现实的问题是:给定算力 C,N 和 D 各取多少 loss 最低?
实验拟合(DeepMind 2022,论文代号 "Chinchilla",以此得名):N 与 D 应等比例增长,最优 D ≈ 20×N。
| 模型 N | 最优 D(token) | 等价多少英文文本† |
|---|---|---|
| 1B | 20B | ~80GB |
| 7B | 140B | ~560GB |
| 70B | 1.4T | ~5.6TB |
经验换算:BPE 下 1 token ≈ 4 bytes 英文(约 3.5–4.5 chars),所以 20B token × 4B ≈ 80GB 纯文本。中文 token 含字数更少(不使用专门针对中文优化的分词时),同 token 数对应文本体量略小。
这是 LLaMA-1(7B 用 1T token,超 Chinchilla 最优 ~7 倍)走向 LLaMA-2/3(持续加大 D)的直接动机:与其堆参数,不如喂更多数据。
过训(over-training)为什么划算? Chinchilla 是 "训练算力固定时 loss 最低" 的解,但 部署后的推理成本与 N 成正比、与 D 无关。一个用 7× 数据训出的 7B 模型,推理时与 7B 同档;而要达到同等质量直接堆参数到 13B/30B,每次推理都贵几倍。LLaMA 系列的 "克制参数量 + 多数据 + 长训" 哲学就是用一次性多花的训练算力换 N 年的推理便宜。Qwen / Mistral 以及本项目将要训练的 echo 全沿用这套路。
"你的模型欠训" 几乎是所有小预算训练的真相。echo-mini ~30M,按 Chinchilla 应该喂 600M token。少喂直接表现为 loss 没下来 + 续写质量差/不连贯。
4.3 对 echo-mini 的启示¶
- 参数 ~30M → Chinchilla 目标 D ≈ 600M token;实际能弄到的语料量级约 100M(几十 GB 中英纯文本不容易凑),已知会欠训,目标只是 "能续写" 而非 "质量好"
- 算力预估(按实际 D=100M 算,欠训跑完):
- C ≈ 6 × 30M × 100M = 1.8e16 FLOPs
- 3060 12GB ~10 TFLOPS(Tera FLOPS,每秒万亿次浮点运算)bf16 理论值,训练实际利用率 ~30% → 有效 ~3 TFLOPS = 3e12 FLOPs/s
- 训练时:1.8e16 / 3e12 ≈ 6000 秒 ≈ 1.7 小时(不计 dataloader / checkpoint IO 等开销)
- batch / lr / 训练步数:抄 nanoGPT/MiniMind 的配方,别从零调
自检¶
- C ≈ 6ND 这个 6 的来源是什么?
- 给你 1×3060 12GB 语料充足训 24 小时,你能训多大模型?(给出量级估算)
答案速查
-
一次前向 ~2ND FLOPs(每 token、每参数算 1 次乘 + 1 次加 = 2 次浮点);反向约前向的 2 倍 → 4ND。前+反共 6ND
-
3060 12GB bf16 ~10 TFLOPS 理论值,训练实际利用率 ~30% → 有效 ~3 TFLOPS = 3e12 FLOPs/s。24h = 8.6e4s。总算力 ~2.6e17 FLOPs。按 C=6ND 且 D=20N(Chinchilla),算出 N ≈ √(C/120) ≈ 1.5e7 = 15M 参数。所以3060 12GB 24 小时只够训 echo-mini 量级(注意与上方启示中欠训前提计算的区别),不可能训 1B+。这是为什么本项目把 "从零训" 和 "微调底座" 分两线
5. 练习¶
落到 Playground/ch09-pretrain/:
| 脚本 | 内容 |
|---|---|
01_clm_loss.py |
手动 shift 算 loss,与 HF 风格 labels= 自动 shift 对比;演示 ignore_index=-100 的效果 |
02_packing.py |
把若干变长 "假文档" 做 packing,对比 padding 与 packing 的有效 token 比例 |
03_amp_gradacc.py |
在小 MiniGPT 上分别开 / 关 AMP + grad accumulation + checkpointing,打印显存与时间对比 |
跑法:
uv run python Playground/ch09-pretrain/01_clm_loss.py
uv run python Playground/ch09-pretrain/02_packing.py
uv run python Playground/ch09-pretrain/03_amp_gradacc.py
03 在 CPU/MPS(Metal Performance Shaders,苹果 GPU 加速后端)上 grad checkpoint 时间收益不明显(CUDA 上才显著),但 API 调用方式相同,验证代码能跑通即可。
思考题¶
- 为什么 LLaMA-3 用 15T token 训 8B(远超 Chinchilla 的 160B),仍说 "未饱和"?这违反 scaling law 吗?
- 你能想到哪些数据 packing 之外的 "省吞吐" 手段?(提示:dataloader workers / pinned memory / fused optimizer / FSDP(Fully Sharded Data Parallel,完全分片数据并行))
- 推理阶段(ch07 KV cache)和训练阶段(本章 packing)对显存的诉求完全不同,能从这种差异看出什么工程哲学?
参考资料¶
- Kaplan et al., "Scaling Laws for Neural Language Models" (2020):scaling law 起源
- Hoffmann et al., "Training Compute-Optimal Large Language Models" (Chinchilla, 2022):D=20N 的来源
- Karpathy, nanoGPT:极简 GPT pretrain,本章三件套全有 → https://github.com/karpathy/nanoGPT
- PyTorch AMP 官方文档:https://pytorch.org/docs/stable/amp.html
- MiniMind:从零训 26M 中文小模型的开源参考,预训练配方完整 → https://github.com/jingyaogong/minimind